Search engines are an extremely powerful tool of promoting your business websites online and getting target customers. Many studies have shown that between 40% and 80% of users found what they were looking for by using the search engine feature of the Internet. According to a research it is concluded that 625 million searches are performed every day!
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results. The great thing about search engines is they bring targeted traffic to your website. These people are already motivated to make a purchase from you- because they searched you out.
With the right website optimization, the search engines can always deliver your site to your audiences.
4 types of Search engines mostly used are:
1. Crawler-Based Search Engines
2. Human Powered Directories
3. Hybrid Search Engines
4. Meta Search Engines
1- Crawler-based search engines
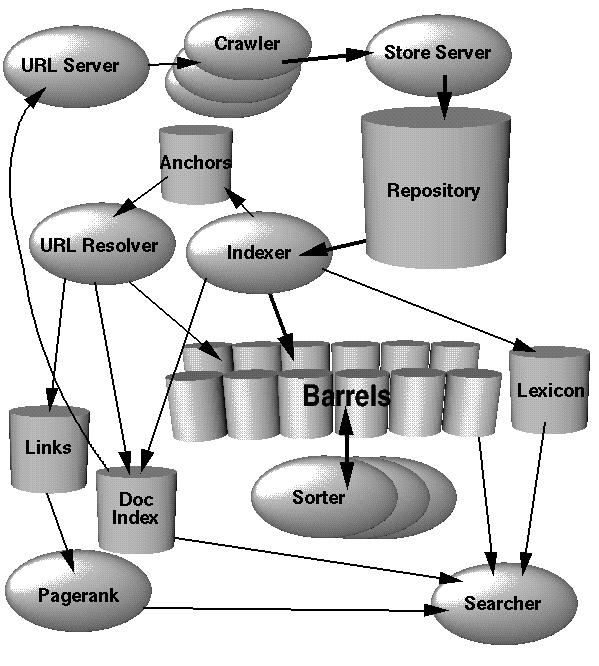
Crawler-based search engines use automated software programs to survey and categorize web pages. The programs used by the search engines to access your web pages are called ‘spiders’, ‘crawlers’, ‘robots’ or ‘bots’.
A spider will find a web page, download it and analyze the information presented on the web page. The web page will then be added to the search engine’s database. Then when a user performs a search, the search engine will check its database of web pages for the key words the user searched on to present a list of link results.
The results (list of suggested links to go to), are listed on pages by order of which is ‘closest’ (as defined by the ‘bots’), to what the user wants to find online. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.
Examples:
Examples of crawler-based search engines are:
* Google (www.google.com)
* Ask Jeeves (www.ask.com)
2- Human Powered Directories
A human-powered directory depends on humans for its listings. A directory gets its information from submissions, which include a short description to the directory for the entire site, or from editors who write one for sites they review. Human editors who decide what category the site belongs to; they place websites within specific categories in the ‘directories’ database. The human editors comprehensively check the website and rank it, based on the information they find, using a pre-defined set of rules.
Examples:
There are two major directories at the time of writing:
* Yahoo Directory
* Open Directory
3- Hybrid Search Engines
Hybrid search engines use a combination of both crawler-based results and directory results. It is extremely common for crawler-type and human-powered results to be combined when conducting a search. Usually, a hybrid search engine will favor one type of listings over another. For example, MSN Search is more likely to present human-powered listings from LookSmart.
More and more search engines these days are moving to a hybrid-based model. Example of hybrid search engine is MSN.
4- Meta Search Engines
Meta search engines take the results from all the other search engines results, and combine them into one large listing.
Examples:
Examples of Meta search engines include:
* Metacrawler
* Dogpile
NexGen Forum provides a platform to learn, discuss, share, and find tutorials on Search engine discussion and marketing, including SEO, Paid marketing and Affiliate marketing. Latest updates of Search engine optimization techniques, Google Adwords, effective online marketing tactics and affiliate marketing all at NexGen forum.
A web search engine is designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results. The great thing about search engines is they bring targeted traffic to your website. These people are already motivated to make a purchase from you- because they searched you out.
With the right website optimization, the search engines can always deliver your site to your audiences.
4 types of Search engines mostly used are:
1. Crawler-Based Search Engines
2. Human Powered Directories
3. Hybrid Search Engines
4. Meta Search Engines
1- Crawler-based search engines
Crawler-based search engines use automated software programs to survey and categorize web pages. The programs used by the search engines to access your web pages are called ‘spiders’, ‘crawlers’, ‘robots’ or ‘bots’.
A spider will find a web page, download it and analyze the information presented on the web page. The web page will then be added to the search engine’s database. Then when a user performs a search, the search engine will check its database of web pages for the key words the user searched on to present a list of link results.
The results (list of suggested links to go to), are listed on pages by order of which is ‘closest’ (as defined by the ‘bots’), to what the user wants to find online. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.
Examples:
Examples of crawler-based search engines are:
* Google (www.google.com)
* Ask Jeeves (www.ask.com)
2- Human Powered Directories
A human-powered directory depends on humans for its listings. A directory gets its information from submissions, which include a short description to the directory for the entire site, or from editors who write one for sites they review. Human editors who decide what category the site belongs to; they place websites within specific categories in the ‘directories’ database. The human editors comprehensively check the website and rank it, based on the information they find, using a pre-defined set of rules.
Examples:
There are two major directories at the time of writing:
* Yahoo Directory
* Open Directory
3- Hybrid Search Engines
Hybrid search engines use a combination of both crawler-based results and directory results. It is extremely common for crawler-type and human-powered results to be combined when conducting a search. Usually, a hybrid search engine will favor one type of listings over another. For example, MSN Search is more likely to present human-powered listings from LookSmart.
More and more search engines these days are moving to a hybrid-based model. Example of hybrid search engine is MSN.
4- Meta Search Engines
Meta search engines take the results from all the other search engines results, and combine them into one large listing.
Examples:
Examples of Meta search engines include:
* Metacrawler
* Dogpile
NexGen Forum provides a platform to learn, discuss, share, and find tutorials on Search engine discussion and marketing, including SEO, Paid marketing and Affiliate marketing. Latest updates of Search engine optimization techniques, Google Adwords, effective online marketing tactics and affiliate marketing all at NexGen forum.